I also posted this over at our Kabbage Tech Blog
At Kabbage, my team loves using Docker! We get a ton of parity between our development, testing and production environments.
We package up our code, configuration and system dependencies into a Docker image. That image becomes our immutable deployment unit.
I’ll cover how we build and package repeatable Docker images in another post. For now lets talk about how we deploy and run these images.
Too many cooks options
You have many options for managing the deployment and operation of your docker images. Early into our first Docker project, I assumed we’d use Shipyard for orchestration.
It had a nice GUI and an API. I’d planned to script Shipyard’s API to get the images and containers onto the hosts.
I found out the hard way that Shipyard can’t pull images onto remote Docker hosts! I thought for a hot minute about scripting something to handle that part. But that seemed more complicated than it was worth.
So I started running down the list with not much time left to get a working solution…
Panamax.io — Had a GUI and an API but seemed way more complex than what we needed.
Fig/docker-compose — We were already using fig for our local development environments. Managing remote docker hosts isn’t its strong suit. It’s possible but slow because you deploy to each host in sequence.
Centurion — Looked promising. It was fig, but for remote systems. New Relic wrote it so it’s got some real-world usage. But the first thing I ran into when using it was Ruby traceback. I could’ve spent my time diagnosing it, but I had one more tool to try out.
maestro-ng — Looked a lot like Centurion and fig. It could pull images onto remote docker hosts, check! It’s written in Python, so if I ran into a problem I had a better chance of fixing the problem quickly.
Maestro-ng’s the winner
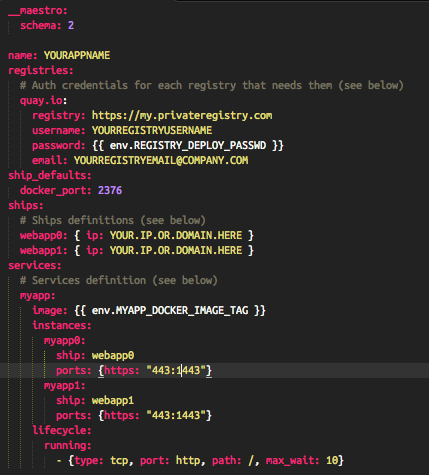
Maestro is a lot like fig. You configure your container — which image, environment variables, volumes, links, etc. — in a YAML file. You also configure the remote docker hosts, or “ships.”
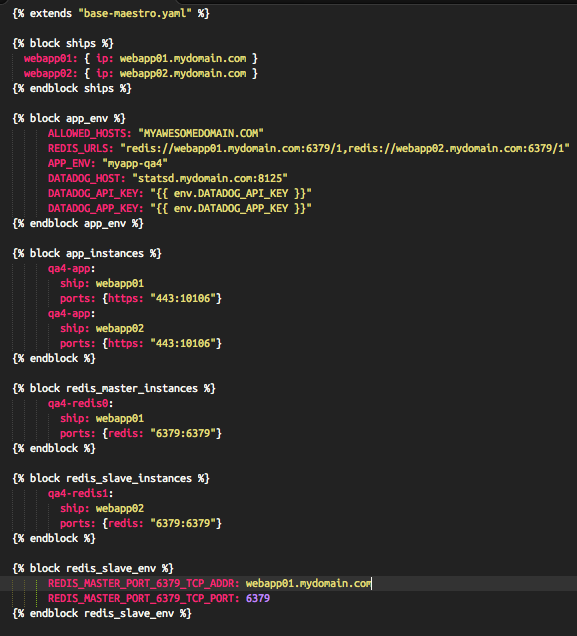
Plus, under the hood the yaml files are treated as Jinja2 templates. You can keep your configuration DRY with a base template for an application. In per-environment yaml files, you change only what’s needed!
Deployment is a breeze. We use a Blue/Green deployment strategy so we can safely stop the running containers on our hosts. Here’s what our deploy script looks like:
# pull new image onto box maestro -f $maestro_file pull $service # stop the running service maestro -f $maestro_file stop $service # clean out old containers maestro -f $maestro_file clean $service # start the new containers with the new image maestro -f $maestro_file start $service