I also posted this over at our Kabbage Tech Blog
In the five months my team’s been using Docker we’ve stolen adopted some standards to make our lives easier.
1. Build your own critical base images
Our application images have their own FROM inheritance chain. The application image depends on a Python Web application base image.
That web app image depends on an official Python image, which in turn depends on a Debian official image.
Those images are subject to change at the whim of their Github committers. Having dependencies change versions on you without notice is not cool.

So we cloned the official Dockerfiles into our own git repo. We built the images and store them in our own Docker registry.
Every time we build our base or application images we know that nothing critical has changed out from underneath us.
2. Container expectations
Stop. Go read Shopify’s post on their container standards. The next section will now seem eerily similar because we stole adopted a bunch of their recommendations.
container/files/
We copy everything in ./container/files over the root filesytem. This lets you add or override just about system config file that your application needs.
container/test
We expect this script to test your application, duh. Ours are shell scripts that run the unit, integration or complexity tests based on arguments.
Testing your app becomes a simple command:
docker-compose run web container/test [unit|pep8|ui|complexity]
container/compile
We run this script as the last step before the CMD gets run.
This is what ours looks like:
echo "$(git rev-parse --abbrev-ref HEAD)--$(git rev-parse --short HEAD)" > /app/REVISION
echo "Bower install"
node node_modules/bower/bin/bower install
echo "Big Gulp build - minification"
node node_modules/gulp/bin/gulp.js build
/venv/bin/python /app/manage.py collectstatic --noinput
3. Docker optimization
ADD, install, ADD
We run docker build a lot. Every developer’s push to a branch kicks off a docker build / test cycle on our CI server. So making docker build as fast as possible is critical to a short feedback loop.
Pulling in libraries via pip and npm can be slow. So we use the ADD, install, ADD method:
# Add and install reqs
ADD ./requirements.txt /app/
RUN /venv/bin/pip install -r /app/requirements.txt
# Add ALL THE CODEZ
ADD . /app
By adding and then installing requirements.txt, Docker can cache that step. You’ll only have to endure a re-install when you change something in your requirements.txt.
If you go the simpler route like below, you’d suffer a pip install every time you change YOUR code:
# Don't do this
ADD . /app
RUN /venv/bin/pip install -r /app/requirements.txt
Install & cleanup in a layer
We also deploy a lot. After every merge to master, an image gets built and deployed to our staging environment. Then our UI tests run and yell at us if we broke something.
Sometimes you need to install packages to compile your application’s dependencies. The naive approach to this looks like this:
RUN apt-get update -y
RUN apt-get install libglib2.0-dev
RUN pip install -r requirements.txt # has something that depends on libglib
RUN apt-get remove libglib2.0-dev
RUN apt-get autoremove
The problem with that approach is that each command creates a new layer in your docker image. So the layer that adds libglib will always be a contributor to your image’s size, even when you remove the lib a few commands later.
Each instruction in your Dockerfile will only ever increase the size of your image.
Instead, move add-then-install-then-delete steps into a script you call from your Dockerfile. Ours looks something like this:
#Dockerfile
ADD ./container/files/usr/local/bin/install_and_cleanup.sh /usr/local/bin/
RUN /usr/local/bin/install_and_cleanup.sh
#install_and_cleanup.sh
set -e # fail if any of these steps fail
apt-get -y update
apt-get -y install build-essential ... ... ...
#... do some stuff ...
apt-get remove -y build-essential ...
apt-get autoremove -y
rm -rf /var/lib/apt/lists/*
For more Docker image optimization tips check out CenturyLink Labs’ great article.
4. Volumes locally, baked in for deployment
While working on our top-of-the-line laptops, we use docker-compose to mount our code into a running container.
But deployment is a different story.
Our CI server bundles our source code, system dependencies, libraries and config files into one authoritative image.
 It’s like this, except not.
It’s like this, except not.
That image is what’s running on our QA, staging and production servers. If we have an issue, we can pull an exact copy of what’s live from the registry to diagnose on our laptops.
5. One purpose (not process) per container
Some folks are strict, die-hard, purists that insist you only run one process in a container. One container for nginx, one container for uwsgi, one container for syslog, etc.
We take a more pragmatic approach of one purpose per container. Our web application containers run nginx and uwsgi and syslog. Their purpose is to serve our Web application.
One container runs our Redis cache, it’s purpose is to serve our Redis cache. Another container serves our Redis sentinel instance. Another serves our OpenLDAP instances. And so on….
I’d rather have a moderate increase in image size (by adding processes related to the purpose). It’s better than having to orchestrate a bunch more containers to serve a single purpose.
6. No Single Points of Failure

Docker makes it super-easy to deploy everything to a single host and hook them up via Docker links.
But then you’re a power-cycle away from disaster.
Docker is an amazing tool that makes a lot of things way easier. But you still need to put thought and effort into what containers you deploy onto what hosts. You’ll need to plan a load balancing strategy for your apps, and failover or cluster strategy for your master databases, etc.
Future standards
Docker is ready for prime time production usage, but that doesn’t mean it or its ecosystem is stagnant. There are a couple of things to consider going forward.
Docker 1.6 logging/syslog
Docker 1.6 introduces the concept of a per-host (not per-container) logging driver. In theory this would let us remove syslog from our base images. Instead we’d send logs from the containers, via the Docker daemon, to syslog installed on the host itself.
Docker Swarm
Docker swarm is a clustering system. As of this writing it’s at version 0.2.0 so it’s still early access.
Its promise is to take a bunch of Docker hosts and to treat them as if they’re one giant host. You tell Docker swarm “Here’s a container, get it running. I don’t need to know where!”
There’s features planned but not implemented that would allow you to use it without potentially creating the aforementioned single point of failure.
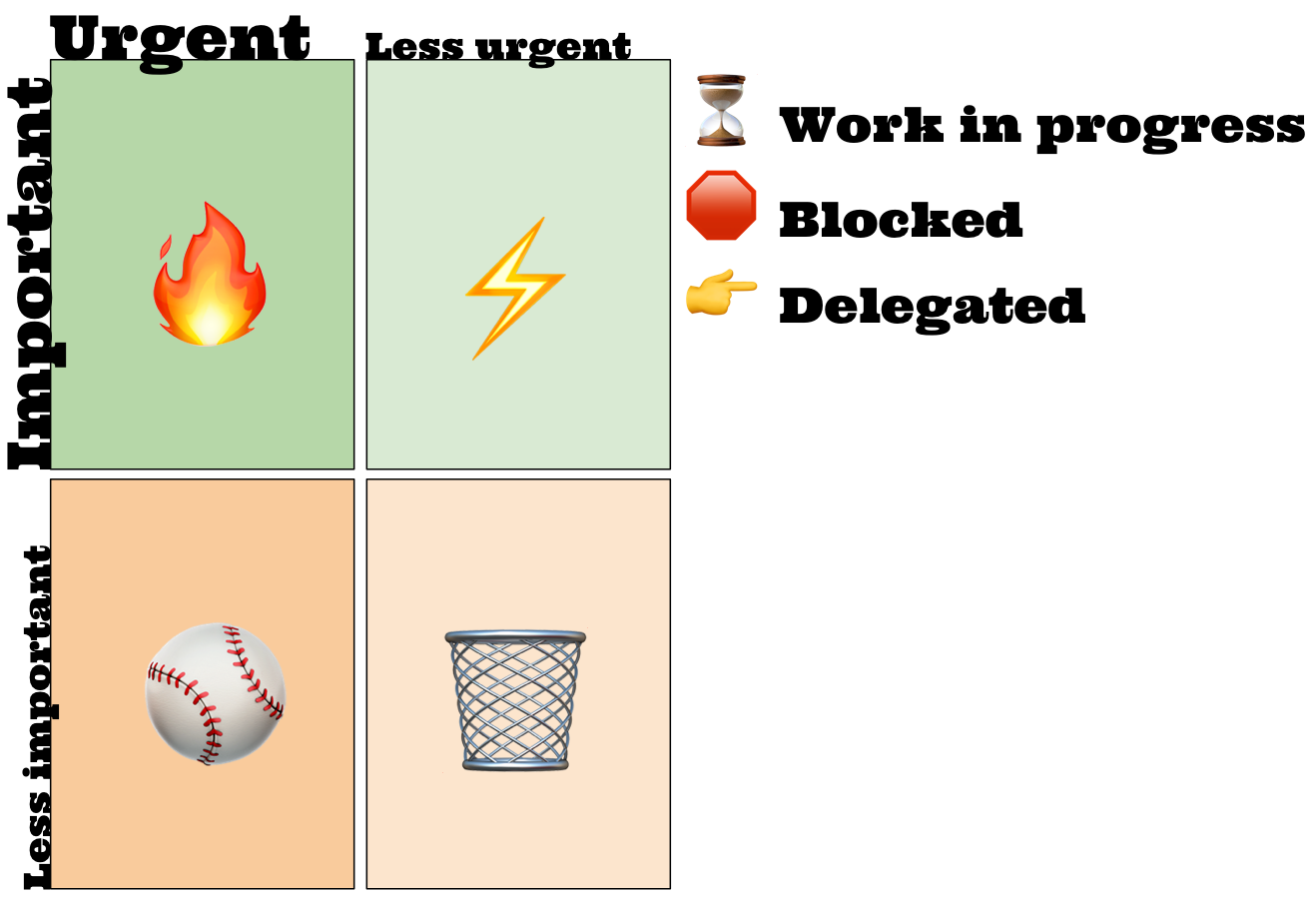
 For me, a successful day doesn’t end once I’ve gotten my priorities straightened out and emoji-fied in Things.app. The next step is to schedule time on my calendar for any todo that needs more than 5 minutes.
For me, a successful day doesn’t end once I’ve gotten my priorities straightened out and emoji-fied in Things.app. The next step is to schedule time on my calendar for any todo that needs more than 5 minutes.